
Sportvorhersagen
Ladevorgang...
Ladevorgang...
Einführung: Warum KI-Value-Tipps das Wetten verändern
Wer in den letzten Jahren die Sportwettenbranche beobachtet hat, dem ist aufgefallen, dass ein Begriff immer häufiger auftaucht: Künstliche Intelligenz. Von Telegram-Kanälen über spezialisierte Websites bis hin zu Apps versprechen unzählige Anbieter, mithilfe von KI die besten Fußballtipps zu liefern. Manche klingen dabei wie Marktschreier auf dem Jahrmarkt, andere präsentieren sich seriöser. Doch was steckt wirklich dahinter? Und vor allem: Kann man mit KI-generierten Value-Tipps tatsächlich langfristig erfolgreicher wetten?
Die Antwort ist, wie so oft bei komplexen Fragen, weder ein eindeutiges Ja noch ein klares Nein. Sie hängt davon ab, wie man diese Werkzeuge versteht und einsetzt. Fußball produziert seit Jahren eine geradezu absurde Menge an Daten. Jeder Zweikampf, jeder Passweg, jede Laufbewegung wird erfasst und in Datenbanken gespeichert. Diese Informationsflut zu verarbeiten, Muster zu erkennen und daraus Schlüsse zu ziehen – genau das ist die Stärke von Machine-Learning-Algorithmen. Kein menschlicher Analyst kann 50.000 Spiele durchforsten und dabei noch jeden einzelnen Schuss nach Winkel, Distanz und Körperposition bewerten. Eine gut trainierte KI schon.
Gleichzeitig wäre es naiv zu glauben, dass ein Algorithmus das Unberechenbare berechenbar macht. Fußball bleibt Fußball. Der Ball ist rund, das Spiel dauert 90 Minuten, und am Ende gewinnt nicht immer der Bessere. Ein Elfmeter wird verschossen, ein abgefälschter Schuss trudelt ins Netz, ein Schiedsrichter trifft eine fragwürdige Entscheidung – all das kann keine KI der Welt zuverlässig vorhersagen. Was sie aber kann: die Wahrscheinlichkeit bestimmter Ereignisse präziser einschätzen als der durchschnittliche Wetter, der am Samstagnachmittag nach Bauchgefühl tippt.
In diesem Leitfaden geht es nicht darum, Wunder zu versprechen. Es geht darum, zu verstehen, wie KI-basierte Value-Tipps funktionieren, welche Daten einfließen, welche Methoden zum Einsatz kommen und wie man das Ganze realistisch einordnet. Dabei werden wir uns mit allem beschäftigen, was für eine fundierte Einschätzung notwendig ist: von den mathematischen Grundlagen der Value-Berechnung über die Rolle von Expected Goals bis hin zu den Grenzen dessen, was selbst die beste KI leisten kann. Wer nach dem Lesen dieses Artikels immer noch glaubt, es gäbe eine KI, die sichere Gewinne garantiert, hat vermutlich nur die Überschriften überflogen. Wer hingegen bereit ist, sich mit der Materie auseinanderzusetzen, findet hier das Handwerkszeug für einen informierteren Umgang mit Sportwetten – nicht mehr, aber auch nicht weniger.
Die Grundlagen: Was sind KI-generierte Fussball-Tipps?
Bevor man sich in die Tiefen von Algorithmen und Datenmodellen stürzt, sollte man eine grundlegende Frage klären: Was genau meinen wir eigentlich, wenn wir von KI-generierten Fußballtipps sprechen? Der Begriff wird inflationär verwendet, und nicht alles, was sich KI nennt, verdient diesen Namen auch. Manche Anbieter verkaufen simple Excel-Auswertungen als revolutionäre Algorithmen, während andere tatsächlich auf maschinelles Lernen setzen. Die Unterscheidung ist wichtig, denn sie bestimmt, wie viel Vertrauen man den Ergebnissen schenken kann.

Im Kern handelt es sich bei echten KI-Systemen für Sportwetten um Computerprogramme, die mit großen Mengen historischer Fußballdaten trainiert wurden. Sie haben gelernt, aus vergangenen Spielen, Statistiken und Quoten Muster zu erkennen, die für zukünftige Partien relevant sein könnten. Der entscheidende Punkt: Diese Muster müssen nicht offensichtlich sein. Ein menschlicher Analyst erkennt vielleicht, dass Bayern München zu Hause stark ist. Eine gut trainierte KI erkennt möglicherweise, dass Bayern bei Heimspielen nach englischen Wochen gegen Mannschaften, die zuletzt auswärts verloren haben und deren Torwart unter einer bestimmten Körpergröße liegt, besonders viele Standardsituationen erzielt. Ob dieses Muster tatsächlich aussagekräftig ist oder nur statistisches Rauschen, muss sich erst zeigen – aber solche komplexen Zusammenhänge findet kein Mensch durch manuelles Durchblättern von Statistiken.
Die gängigsten Ansätze lassen sich in drei Kategorien einteilen. Erstens gibt es die großen Sprachmodelle wie ChatGPT oder Claude, die ursprünglich nicht für Sportwetten entwickelt wurden, aber für Analysen genutzt werden können. Sie sind gut darin, Kontext zu verstehen und Informationen zusammenzufassen, haben aber einen entscheidenden Nachteil: Sie wurden nicht mit Echtzeit-Fußballdaten trainiert und können daher keine aktuellen Statistiken berücksichtigen, es sei denn, man liefert sie ihnen manuell. Zweitens existieren spezialisierte Sportwetten-Algorithmen, die von Grund auf für diesen Zweck entwickelt wurden. Sie arbeiten mit tagesaktuellen Daten und sind darauf optimiert, Wahrscheinlichkeiten für Spielausgänge zu berechnen. Drittens kombinieren hybride Systeme beide Ansätze, indem sie die Kontextfähigkeiten großer Sprachmodelle mit den Rechenfähigkeiten spezialisierter Algorithmen verbinden.
Was diese Systeme gemeinsam haben: Sie produzieren keine Gewissheiten, sondern Wahrscheinlichkeiten. Eine KI sagt nicht: Bayern gewinnt. Sie sagt: Die Wahrscheinlichkeit, dass Bayern gewinnt, liegt bei 68 Prozent. Das klingt nach einem kleinen Unterschied, ist aber fundamental. Denn diese Wahrscheinlichkeit kann man mit der vom Buchmacher implizierten Wahrscheinlichkeit vergleichen – und genau hier beginnt das Konzept des Value, auf das wir im nächsten Abschnitt eingehen.
Das Value-Konzept: Mehr als nur Wahrscheinlichkeiten
Das Missverständnis, das den meisten Wettern zum Verhängnis wird, lässt sich in einem Satz zusammenfassen: Sie versuchen, Spiele vorherzusagen, statt profitable Wetten zu finden. Der Unterschied mag spitzfindig klingen, ist aber der Kern jeder ernsthaften Wettstrategie. Es geht nicht darum, möglichst oft richtig zu liegen. Es geht darum, Wetten zu platzieren, deren erwarteter Ertrag positiv ist. Eine Wette kann falsch sein und trotzdem eine gute Entscheidung gewesen sein – und umgekehrt.
Das Konzept dahinter nennt sich Value Bet, und es basiert auf einer simplen Überlegung: Buchmacher sind nicht allwissend. Sie berechnen Quoten auf Basis ihrer eigenen Wahrscheinlichkeitseinschätzung und fügen eine Marge hinzu, um Profit zu machen. Dabei unterlaufen ihnen Fehler. Manchmal setzen sie die Wahrscheinlichkeit eines Ereignisses zu niedrig an, was zu einer höheren Quote führt, als mathematisch gerechtfertigt wäre. Wer solche Diskrepanzen systematisch findet und ausnutzt, hat langfristig einen Vorteil – selbst wenn einzelne Wetten verloren gehen.
Ein Beispiel macht das greifbarer. Nehmen wir an, der Buchmacher bietet eine Quote von 2,50 auf den Sieg einer Auswärtsmannschaft. Diese Quote impliziert eine Wahrscheinlichkeit von 40 Prozent, denn 1 geteilt durch 2,50 ergibt 0,40. Jetzt kommt die KI ins Spiel: Sie analysiert historische Daten, aktuelle Form, xG-Werte, Verletzungen und hundert weitere Faktoren und kommt zu dem Schluss, dass die tatsächliche Siegwahrscheinlichkeit bei 48 Prozent liegt. Die Differenz von 8 Prozentpunkten ist der Value. Wenn die KI-Schätzung korrekt ist, macht diese Wette langfristig Gewinn, auch wenn sie in diesem konkreten Fall verloren gehen kann.
Warum ist KI für diese Art der Analyse besonders geeignet? Weil die Berechnung präziser Wahrscheinlichkeiten aus komplexen, vieldimensionalen Datensätzen genau das ist, wofür Machine-Learning-Algorithmen entwickelt wurden. Ein Mensch kann nicht gleichzeitig die Heimstärke, die Auswärtsform, die xG-Differenz, die Verletzungssituation, die Belastung durch Europapokal, das historische Abschneiden gegen ähnliche Gegner und die Quotenbewegung der letzten 48 Stunden berücksichtigen. Eine KI kann das – zumindest im Prinzip. Ob sie es auch gut macht, ist eine andere Frage, die von der Qualität des Modells, der Datengrundlage und dem Training abhängt. Der entscheidende Punkt bleibt jedoch: Value-Betting ist keine Frage von Glück oder Bauchgefühl, sondern eine mathematische Disziplin, und Mathematik ist das natürliche Terrain von Computern.
Die Datenbasis: Welche Informationen füttert man einer KI?
Ein KI-Modell ist nur so gut wie die Daten, mit denen es trainiert und gefüttert wird. Diese Binsenweisheit aus der Informatik gilt für Sportwetten genauso wie für jede andere Anwendung maschinellen Lernens. Wer verstehen will, warum manche KI-Tipps besser sind als andere, muss sich mit der Frage beschäftigen, welche Informationen in die Analyse einfließen – und welche nicht.
Die Basisdaten sind das, was jeder Fußballfan aus dem Fernsehen kennt: Spielergebnisse der letzten Saisons, Heim- und Auswärtsbilanz, Tabellenposition, direkte Duelle zwischen den beiden Teams. Diese Informationen nutzt auch jeder Buchmacher, weshalb sie allein keinen Vorteil verschaffen. Sie sind notwendig, aber nicht hinreichend. Interessant wird es erst bei den erweiterten Statistiken, die über das hinausgehen, was im Sportteil der Tageszeitung steht. Dazu gehören detaillierte Schussdaten, also nicht nur die Anzahl der Torschüsse, sondern auch deren Position, Winkel und Geschwindigkeit. Hinzu kommen Passnetzwerke, die zeigen, welche Spieler wie häufig kombinieren, sowie Pressing-Statistiken, die die Intensität des Gegenpressings nach Ballverlust messen. Moderne Datenlieferanten wie Opta oder StatsBomb erfassen selbst die Laufwege und Sprintdistanzen jedes einzelnen Spielers.
Neben den quantitativen Daten spielen auch Kontextfaktoren eine Rolle, die schwieriger zu erfassen sind. Ein Trainerwechsel kann die Spielweise einer Mannschaft komplett verändern, eine wichtige Verletzung die Balance des Teams zerstören, ein Abstiegskampf die Motivation auf ein anderes Level heben. Diese qualitativen Informationen fließen bei guten KI-Systemen ebenfalls ein, oft in Form von Anpassungsfaktoren, die auf historischen Mustern basieren. Wie hat sich ein Trainerwechsel in der Vergangenheit auf ähnliche Mannschaften ausgewirkt? Wie stark ist der Einfluss eines verletzten Spielers auf die xG-Produktion seines Teams? Solche Fragen lassen sich aus Daten beantworten, erfordern aber ein durchdachtes Modelldesign.
Eine oft unterschätzte Datenquelle ist die Quotenbewegung selbst. Die Opening Line, also die erste Quote, die ein Buchmacher anbietet, unterscheidet sich häufig von der Closing Line kurz vor Spielbeginn. Diese Differenz entsteht durch Wetteinsätze, die den Markt bewegen, und durch neue Informationen wie Aufstellungen oder Last-Minute-Verletzungen. Professionelle Wetter wissen: Die Closing Line ist in der Regel präziser als die Opening Line, weil sie mehr Informationen eingepreist hat. KI-Systeme, die Quotenbewegungen analysieren, können Hinweise darauf finden, wo der Markt möglicherweise falsch liegt oder wo große Summen von informierten Wettern platziert wurden.
Expected Goals (xG): Das Herzstück moderner Fußballanalyse
Wer sich ernsthaft mit datenbasierter Fußballanalyse beschäftigt, kommt an einem Konzept nicht vorbei: Expected Goals, kurz xG. Dieser Wert hat in den letzten Jahren eine bemerkenswerte Karriere hingelegt, von einer Nischenstatistik für Datennerds zum festen Bestandteil der Fußballberichterstattung. Mittlerweile zeigen selbst öffentlich-rechtliche Sender nach Spielen die xG-Werte an, und kein Analystenkommentar kommt ohne den Begriff aus. Für KI-gestützte Value-Tipps ist xG nicht nur ein nettes Add-on, sondern ein fundamentaler Baustein.
Die Grundidee ist elegant einfach: Jede Torchance wird danach bewertet, wie wahrscheinlich es ist, dass sie zu einem Tor führt. Ein Elfmeter hat einen hohen xG-Wert von etwa 0,76, weil rund drei von vier Elfmetern verwandelt werden. Ein Kopfball aus acht Metern nach einer Flanke liegt vielleicht bei 0,08, ein Fernschuss aus 25 Metern bei 0,03. Die Summe aller Torchancen einer Mannschaft ergibt den xG-Wert für das Spiel. Ein Team, das 2,3 xG produziert hat, hätte im statistischen Mittel also 2,3 Tore erzielen sollen – unabhängig davon, wie viele tatsächlich gefallen sind.
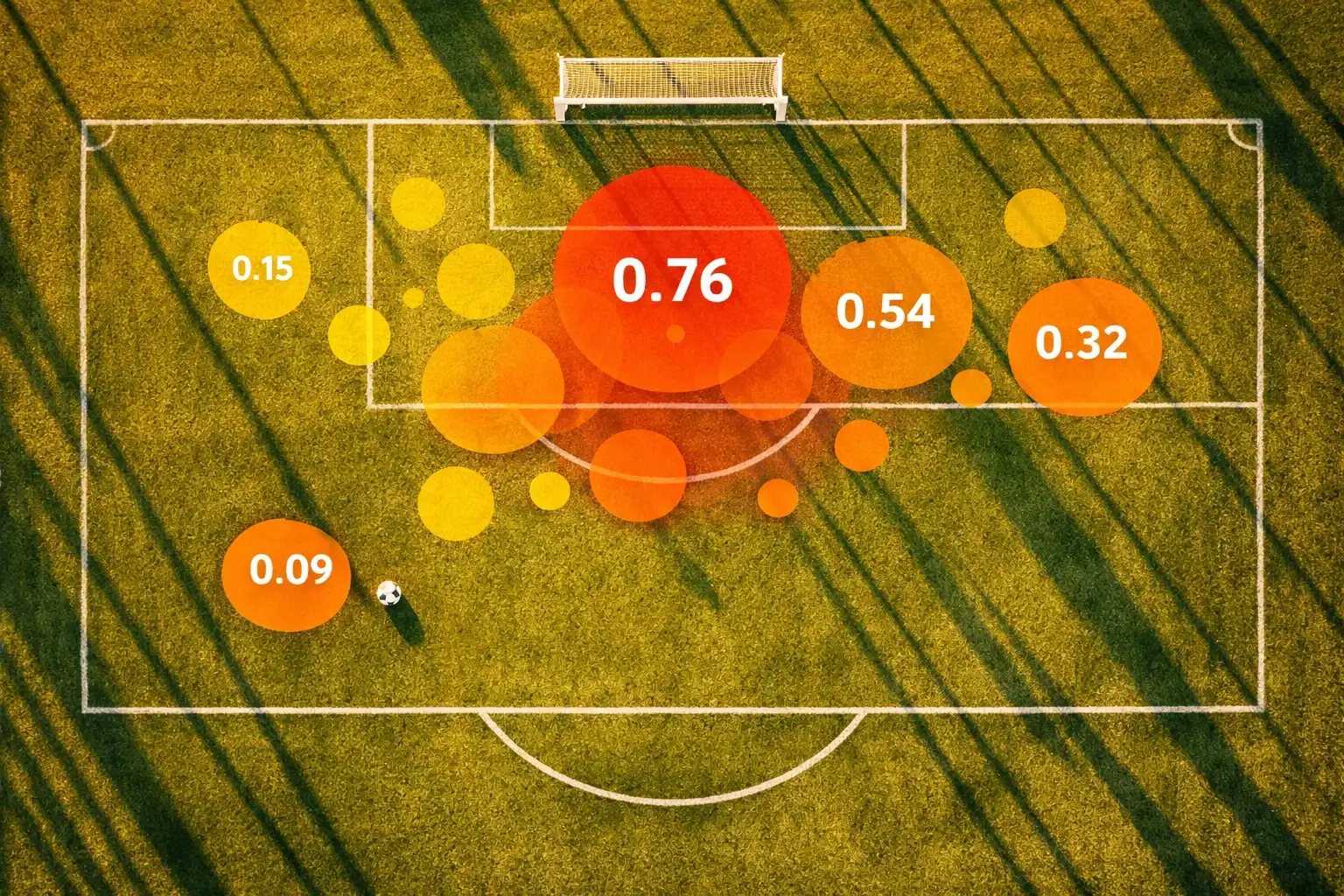
Der Mehrwert für Sportwetten liegt in der Filterung von Zufall. Fußball ist ein Sport mit niedrigem Scoring, was bedeutet, dass Glück und Pech einen erheblichen Einfluss auf Einzelergebnisse haben. Ein Team kann drei Großchancen verschwenden und trotzdem gewinnen, weil ein abgefälschter Schuss ins Netz trudelt. Wer nur auf Ergebnisse schaut, könnte dieses Team für stärker halten, als es ist. Wer xG betrachtet, sieht ein differenzierteres Bild: Das Team hat seine Torchancen nicht genutzt und war vom Ergebnis her glücklich. Für die Zukunft ist das relevant, denn Überperformance gegenüber dem eigenen xG-Wert ist selten nachhaltig. Mannschaften, die konstant mehr Tore erzielen, als ihre Chancenqualität erwarten lässt, haben entweder einen Weltklasse-Stürmer im Kader oder schlicht Glück, das irgendwann endet.
KI-Systeme nutzen xG auf mehreren Ebenen. Zunächst fließen historische xG-Werte in die Modelle ein, um die tatsächliche offensive und defensive Stärke von Teams zu bewerten. Darüber hinaus prognostizieren fortgeschrittene Modelle den erwarteten xG-Wert für kommende Spiele, indem sie die Offensivstärke des einen Teams gegen die Defensivqualität des anderen modellieren. Aus diesen prognostizierten xG-Werten lassen sich dann Wahrscheinlichkeiten für verschiedene Spielausgänge ableiten, die wiederum mit den Buchmacherquoten verglichen werden können.
Allerdings hat auch xG seine Grenzen, die man kennen sollte. Das Modell berücksichtigt nicht die individuelle Qualität des Schützen. Ein Robert Lewandowski, der aus 14 Metern halbrechts abschließt, hat andere Erfolgsaussichten als ein Amateurspieler in derselben Position. Die Torwartleistung wird in vielen xG-Modellen nur unzureichend erfasst, und taktische Anpassungen während des Spiels, etwa nach einem frühen Gegentor, bleiben oft außen vor. Gute KI-Systeme kennen diese Limitierungen und versuchen, sie durch zusätzliche Faktoren zu kompensieren.
Formbasierte Analyse: Der Kontext entscheidet
Statistiken sind das eine, Kontext ist das andere. Ein Team, das in den letzten fünf Spielen 15 Punkte geholt hat, ist nicht automatisch dasselbe Team wie vor einem Monat, als es fünf Niederlagen in Folge kassierte. Form ist im Fußball real, messbar und relevant – auch wenn sie sich nicht so präzise quantifizieren lässt wie ein xG-Wert. KI-Systeme, die nur auf Saisonstatistiken schauen und die aktuelle Dynamik ignorieren, verpassen einen wichtigen Teil des Bildes.
Die Frage ist: Wie weit zurück sollte man schauen, und wie stark sollte man jüngere Spiele gewichten? Ein gängiger Ansatz ist die Analyse der letzten fünf bis zehn Partien, wobei neuere Ergebnisse stärker gewichtet werden als ältere. Das ergibt Sinn, denn ein Sieg vor zwei Wochen ist relevanter als einer vor drei Monaten. Allerdings muss man aufpassen, nicht in die Falle der Überinterpretation zu tappen. Ein Team, das gerade drei Spiele in Folge gewonnen hat, muss nicht zwangsläufig in Form sein – wenn diese Siege gegen Tabellenschlusslichter kamen, sagt das wenig über die Leistungsfähigkeit gegen einen Gegner aus der oberen Tabellenhälfte.
Hier zeigt sich eine Stärke von KI-Modellen: Sie können die Qualität der Gegner einbeziehen und differenzieren zwischen einer Siegesserie gegen schwache Gegner und einer gegen starke. Die Elo-Differenz oder andere Stärkeindikatoren der besiegten Teams fließen in die Bewertung ein, sodass nicht jeder Sieg gleich gewichtet wird. Außerdem lässt sich die Form nach Heim- und Auswärtsspielen trennen, was für manche Teams einen erheblichen Unterschied macht. Ein Verein, der zu Hause eine Festung ist, aber auswärts regelmäßig untergeht, braucht eine differenzierte Betrachtung je nach Spielort.
Ein weiterer Aspekt, der oft übersehen wird, sind Formbrüche. Trainer werden entlassen, wichtige Spieler kehren aus Verletzungen zurück, taktische Systeme werden umgestellt – all das kann die Aussagekraft der jüngsten Ergebnisse relativieren. KI-Systeme können solche Ereignisse einbeziehen, sofern sie in den Trainingsdaten erfasst sind. Die Herausforderung besteht darin, den richtigen Mittelweg zu finden zwischen der Gewichtung aktueller Form und der Berücksichtigung langfristiger Substanz.
Statistische Modelle: Von Poisson bis Machine Learning
Hinter jedem KI-gestützten Fußballtipp steckt ein statistisches Modell, das Wahrscheinlichkeiten berechnet. Die Bandbreite reicht von relativ einfachen Ansätzen, die seit Jahrzehnten bekannt sind, bis hin zu komplexen neuronalen Netzen, deren innere Funktionsweise selbst für Experten schwer nachvollziehbar ist. Wer KI-Tipps nutzen will, muss nicht jedes mathematische Detail verstehen, aber ein Grundverständnis der gängigen Ansätze hilft, die Qualität verschiedener Angebote einzuschätzen.
Die Poisson-Verteilung ist der Klassiker unter den Fußballprognosemodellen und wurde bereits in den 1950er-Jahren für diesen Zweck verwendet. Sie basiert auf der Annahme, dass Tore unabhängige, seltene Ereignisse sind, die einer bestimmten statistischen Verteilung folgen. Aus den durchschnittlichen Torerwartungswerten beider Teams, abgeleitet aus historischen Daten und ligaweiten Durchschnittswerten, lässt sich eine Wahrscheinlichkeitsverteilung für mögliche Endergebnisse berechnen. Der Vorteil dieses Ansatzes liegt in seiner Transparenz: Man kann genau nachvollziehen, wie die Prognose zustande kommt. Der Nachteil ist, dass komplexe Zusammenhänge, etwa zwischen Spielstärke, Taktik und Spielverlauf, nicht berücksichtigt werden.
Elo-basierte Systeme gehen einen Schritt weiter, indem sie die relative Stärke der Teams dynamisch anpassen. Jedes Team erhält einen Elo-Wert, der nach jedem Spiel neu berechnet wird. Siege gegen starke Gegner bringen mehr Punkte als Siege gegen schwache, und die Höhe des Ergebnisses spielt ebenfalls eine Rolle. Aus der Differenz der Elo-Werte vor einem Spiel lassen sich Siegwahrscheinlichkeiten ableiten. Dieses System hat sich in verschiedenen Sportarten bewährt und ist besonders gut darin, langfristige Stärkeverhältnisse abzubilden. Tagesaktuelle Faktoren wie Verletzungen oder Motivationslagen werden allerdings nicht direkt erfasst.
Am anderen Ende des Komplexitätsspektrums stehen neuronale Netze und Deep-Learning-Modelle. Sie können nicht-lineare Zusammenhänge aus Millionen von Datenpunkten lernen und Muster erkennen, die kein Mensch explizit programmieren könnte. Ein neuronales Netz könnte beispielsweise lernen, dass Teams mit einem bestimmten Passmuster in Kombination mit einer bestimmten Defensivausrichtung bei Auswärtsspielen in bestimmten Stadien besonders gut oder schlecht abschneiden – ein Zusammenhang, den kein traditionelles Modell erfassen würde. Der Nachteil: Neuronale Netze sind oft Black Boxes. Warum sie eine bestimmte Prognose abgeben, bleibt unklar, was die Fehlersuche erschwert und Vertrauen erschwert.
Die besten KI-Systeme kombinieren mehrere Ansätze in sogenannten Ensemble-Methoden. Ein Modell ist vielleicht stark bei Heimspielen, ein anderes bei Derbys, ein drittes bei klaren Favoritenrollen. Die Kombination reduziert die Schwächen einzelner Modelle und verbessert die Gesamtgenauigkeit. Wie genau diese Kombination erfolgt, ist das Betriebsgeheimnis der jeweiligen Anbieter.
KI-Simulationen: Tausende virtuelle Spiele für einen Tipp
Eine besonders elegante Methode, um mit der inhärenten Unsicherheit von Fußballspielen umzugehen, sind Monte-Carlo-Simulationen. Der Name klingt nach Casino, und das ist kein Zufall: Die Methode wurde ursprünglich für Glücksspielanalysen entwickelt, bevor sie ihren Weg in Wissenschaft, Finanzwelt und Sportwetten fand. Die Grundidee ist so simpel wie mächtig: Anstatt einmal die Wahrscheinlichkeit zu berechnen, simuliert man dasselbe Ereignis tausende Male mit zufälligen Variationen und schaut, wie oft welches Ergebnis eintritt.

Für ein Fußballspiel bedeutet das: Die KI simuliert die Partie nicht einmal, sondern 10.000 oder 20.000 Mal. In jeder Simulation variieren bestimmte Parameter zufällig innerhalb realistischer Grenzen. Torchancen entstehen oder nicht, Schüsse werden gehalten oder nicht, Elfmeter vergeben oder nicht – alles basierend auf den zuvor berechneten Wahrscheinlichkeiten. Am Ende zählt man aus: In wie vielen der 20.000 Simulationen hat Team A gewonnen? Wie oft endete das Spiel 2:1? Wie oft fielen mehr als 2,5 Tore? Diese Häufigkeiten sind dann die geschätzten Wahrscheinlichkeiten, die mit den Buchmacherquoten verglichen werden können.
Der Vorteil gegenüber deterministischen Modellen liegt in der Erfassung von Varianz. Ein Poisson-Modell sagt vielleicht: Die Wahrscheinlichkeit für einen Heimsieg liegt bei 45 Prozent. Eine Simulation liefert nicht nur diese Zahl, sondern zeigt auch die Verteilung der möglichen Ergebnisse. Vielleicht gewinnt das Heimteam in den Simulationen oft knapp mit 1:0 oder 2:1, während hohe Siege selten sind. Diese Zusatzinformation kann für bestimmte Wettmärkte, etwa Handicaps oder exakte Ergebnisse, wertvoll sein.
Moderne Simulationen gehen über einfache Torwahrscheinlichkeiten hinaus und modellieren den Spielverlauf dynamisch. Ein frühes Tor verändert die Dynamik: Das führende Team kann sich zurückziehen, das zurückliegende muss offensiver spielen, was Räume öffnet. Rotationsentscheidungen, Wechsel und taktische Anpassungen fließen ebenfalls ein. Je mehr Faktoren berücksichtigt werden, desto realistischer wird die Simulation – aber auch desto größer wird der Rechenaufwand und die Gefahr, dass kleine Fehler in den Eingabeparametern zu großen Verzerrungen führen. Die Kunst liegt darin, die richtige Balance zu finden zwischen Komplexität, die Realismus erhöht, und Einfachheit, die Robustheit garantiert. Die besten Modelle sind nicht unbedingt die kompliziertesten, sondern jene, die mit dem verfügbaren Datenmaterial am effektivsten umgehen.
Value-Berechnung in der Praxis: Die Formel zum Erfolg
Theorie ist gut, Praxis ist besser. Wie berechnet man also konkret, ob eine Wette Value hat? Die Formel ist erfreulich simpel: Value = Quote multipliziert mit der geschätzten Wahrscheinlichkeit, minus 1. Wenn das Ergebnis positiv ist, liegt Value vor. Wenn es negativ ist, sollte man die Finger von dieser Wette lassen, selbst wenn man das Ergebnis für wahrscheinlich hält.
Ein Rechenbeispiel: Der Buchmacher bietet eine Quote von 2,20 auf den Heimsieg. Diese Quote impliziert eine Wahrscheinlichkeit von etwa 45 Prozent, denn 1 geteilt durch 2,20 ergibt 0,4545. Die KI-Analyse kommt jedoch zu dem Schluss, dass die tatsächliche Heimsiegwahrscheinlichkeit bei 52 Prozent liegt. Die Rechnung lautet nun: 2,20 mal 0,52 ergibt 1,144. Abzüglich 1 erhalten wir 0,144 oder 14,4 Prozent Value. Diese Wette hat einen positiven erwarteten Ertrag. Würde man sie hundertmal platzieren mit korrekter Wahrscheinlichkeitsschätzung, würde man langfristig Gewinn machen.
Der Knackpunkt liegt natürlich in der Wahrscheinlichkeitsschätzung. Die ganze Value-Rechnung steht und fällt mit der Qualität der KI-Prognose. Wenn die KI systematisch daneben liegt, nützt die schönste Formel nichts. Deshalb ist es wichtig, nicht blind jedem Tipp zu folgen, sondern die Plausibilität zu hinterfragen. Stimmen die Eingangsdaten? Wurden wichtige Faktoren berücksichtigt? Ist die prognostizierte Wahrscheinlichkeit im Einklang mit dem, was man selbst beobachtet hat? Skepsis ist angebracht, Vertrauen muss man sich verdienen.
Ein weiterer praktischer Aspekt ist die Frage, ab welchem Value eine Wette lohnenswert ist. Theoretisch reicht jeder positive Wert. Praktisch sollte man einen Sicherheitspuffer einkalkulieren, um Fehler in der Schätzung und die Varianz abzudecken. Viele erfahrene Wetter setzen erst ab einem Value von 5 bis 10 Prozent, manche sogar erst ab 15 Prozent. Je höher die Hürde, desto weniger Wetten qualifizieren sich, aber desto größer ist die Marge pro Wette. Die richtige Balance hängt von der individuellen Risikobereitschaft und dem Vertrauen in die KI-Prognosen ab.
Die wichtigsten KI-Tools und Plattformen im Überblick
Der Markt für KI-basierte Fußballanalysen ist unübersichtlich, und neue Anbieter tauchen ständig auf. Ohne konkrete Produkte zu empfehlen, da sich Qualität und Verfügbarkeit ändern können, lassen sich die wichtigsten Kategorien von Tools beschreiben, die für Value-Tipps relevant sind.
Spezialisierte Sportwetten-KI-Plattformen bilden die erste Kategorie. Sie wurden von Grund auf für die Analyse von Fußballspielen und die Erkennung von Value-Wetten entwickelt. Typischerweise bieten sie tägliche Tipps mit Wahrscheinlichkeitsangaben, Quotenvergleiche verschiedener Buchmacher und historische Performance-Statistiken. Die Qualität variiert stark, und viele nutzen den Begriff KI eher als Marketinglabel denn als akkurate Beschreibung ihrer Methodik. Seriöse Anbieter legen offen, welche Datenquellen und Modelltypen sie verwenden.
Die zweite Kategorie umfasst allgemeine KI-Modelle wie ChatGPT oder Claude, die nicht speziell für Sportwetten entwickelt wurden, aber für Analysen genutzt werden können. Ihre Stärke liegt im Verständnis von Kontext und der Fähigkeit, Informationen zusammenzufassen. Ihre Schwäche: Sie haben keinen direkten Zugriff auf aktuelle Spielstatistiken und können keine Wahrscheinlichkeiten im engeren Sinne berechnen. Für die Recherche und Einschätzung qualitativer Faktoren wie Trainerwechsel oder Motivationslagen können sie dennoch nützlich sein.
Die dritte Kategorie sind statistische Datenbanken, die zwar keine Tipps liefern, aber die Rohdaten, aus denen man selbst Analysen erstellen kann. Understat spezialisiert sich auf xG-Daten, FBref bietet umfassende Statistiken zu vielen Ligen, Transfermarkt liefert Marktwerte und Kaderdaten. Für fortgeschrittene Nutzer, die eigene Modelle entwickeln oder KI-Tipps überprüfen wollen, sind diese Quellen unverzichtbar. Sie erfordern allerdings Zeit und statistisches Grundwissen.
Wer KI-Tools nutzt, sollte kritisch bleiben. Ein Algorithmus ist nur so gut wie seine Eingabedaten und sein Design. Track Records können manipuliert sein, und vermeintlich beeindruckende Trefferquoten relativieren sich schnell, wenn man die Quoten einbezieht. Eine Trefferquote von 60 Prozent klingt gut, ist aber wertlos, wenn alle Tipps auf Quoten unter 1,50 gesetzt wurden.
Risikomanagement: Verantwortungsvolles Wetten mit KI-Unterstützung
Jetzt kommt der Teil, den niemand gerne liest, der aber der wichtigste dieses ganzen Artikels sein könnte: Risikomanagement. Denn selbst die beste KI der Welt ändert nichts an einer fundamentalen Tatsache: Sportwetten sind Glücksspiel. Sie können Geld gewinnen, aber auch verlieren. Wer das ignoriert oder verdrängt, hat ein Problem, das keine Technologie lösen kann.

Wichtiger Hinweis: Die Grundregel lautet: Setze nie mehr, als du verlieren kannst. Das klingt banal, wird aber erschreckend oft ignoriert. Eine gängige Empfehlung ist, pro Einzelwette maximal 1 bis 3 Prozent der Bankroll zu setzen, also des Geldes, das man insgesamt für Wetten eingeplant hat. Bei einer Bankroll von 500 Euro wären das 5 bis 15 Euro pro Wette. Das mag wenig klingen, schützt aber vor dem Ruin bei einer unvermeidlichen Pechsträhne. Denn selbst mit perfekter Value-Erkennung wird man Serien von Verlustwetten erleben. Das ist statistisch unvermeidlich und sagt nichts über die Qualität der Strategie.
Realistische Erwartungen sind der zweite Baustein. Langfristiger Erfolg bei Sportwetten bedeutet nicht, 80 Prozent der Wetten zu gewinnen. Es bedeutet, bei einer Trefferquote von vielleicht 52 bis 55 Prozent und durchschnittlichen Quoten um 2,00 langsam, aber stetig Profit zu machen. Das ist weniger spektakulär, als manche Anbieter versprechen, aber es ist realistisch. Wer mehr erwartet, wird früher oder später enttäuscht, und Enttäuschung führt oft zu irrationalem Verhalten: höhere Einsätze, riskantere Wetten, der Versuch, Verluste aufzuholen. Dieser Weg führt selten zu etwas Gutem.
Der dritte Aspekt ist die Selbstreflexion. KI-Tools können die Illusion verstärken, man hätte einen sicheren Vorteil. Diese Überzeugung ist gefährlich, weil sie zu Überheblichkeit führen kann. Wenn mehrere Wetten hintereinander verloren gehen, stellt sich die Frage: Lag es an Pech, oder war die KI-Prognose systematisch falsch? Diese Frage lässt sich nicht nach fünf Wetten beantworten, sondern erst nach Hunderten. Wer nicht bereit ist, seine Strategie langfristig zu dokumentieren und kritisch zu evaluieren, sollte vielleicht überlegen, ob Sportwetten das richtige Hobby sind.
Zuletzt der wichtigste Hinweis: Wenn Wetten kein Spaß mehr macht, wenn man Verluste nicht verkraften kann, wenn man mehr setzt, als man sich leisten kann, dann ist es Zeit, aufzuhören und sich Hilfe zu suchen. Suchtberatungsstellen bieten Unterstützung, und es ist kein Zeichen von Schwäche, diese in Anspruch zu nehmen. In Deutschland gibt es zahlreiche Anlaufstellen, die anonym und kostenlos beraten. Glücksspiel kann süchtig machen, und keine noch so gute KI schützt davor. Das Ziel sollte immer sein, Wetten als das zu betrachten, was es ist: eine Form der Unterhaltung mit finanziellem Risiko, nicht eine Einnahmequelle oder gar ein Weg zum schnellen Reichtum.
Fazit: Der smarte Weg zur KI-gestützten Wettstrategie
Nach dieser ausführlichen Reise durch die Welt der KI-basierten Fußballtipps bleibt die Frage: Was nehmen wir mit? Die Antwort lässt sich in wenigen Kernerkenntnissen zusammenfassen, die als Orientierung dienen können.
Erstens: KI-Value-Tipps sind kein Zaubertrick, sondern ein Werkzeug. Sie können helfen, Wetten mit positivem Erwartungswert zu identifizieren, aber sie garantieren keine Gewinne. Wer die Grundprinzipien versteht, also die Value-Berechnung, die Bedeutung von xG, die Rolle von Form und Kontext, ist besser aufgestellt als jemand, der blind Tipps kopiert. Verständnis schlägt blinden Glauben.
Zweitens: Die Qualität von KI-Prognosen hängt von den Daten und dem Modell ab. Nicht alles, was sich KI nennt, ist auch eine. Skepsis ist angebracht, Track Records sollten verifiziert werden, und Transparenz über Methodik ist ein Qualitätsmerkmal. Wer nicht nachvollziehen kann, wie ein Tipp zustande kommt, sollte vorsichtig sein.
Drittens: Der optimale Ansatz kombiniert KI-Analyse mit menschlichem Urteil. KI ist stark in der Verarbeitung großer Datenmengen und der Erkennung komplexer Muster. Menschen sind stark in der Einschätzung von Kontext, Motivation und qualitativen Faktoren, die schwer zu quantifizieren sind. Die Kombination beider Stärken ist oft besser als jede Komponente allein.
Viertens: Risikomanagement ist nicht optional. Bankroll-Strategie, realistische Erwartungen und die Bereitschaft, Verluste zu akzeptieren, sind die Grundlage jeder nachhaltigen Wettstrategie. Ohne sie ist selbst das beste KI-System wertlos.
Die Technologie wird weitergehen. Bessere Daten, leistungsfähigere Algorithmen, schnellere Verarbeitung – KI-Prognosen werden präziser. Gleichzeitig passen sich Buchmacher an, und der Vorsprung durch KI-Nutzung wird kleiner. Was bleibt, ist die Notwendigkeit, informiert, diszipliniert und realistisch zu agieren. KI kann dabei helfen. Die Arbeit abnehmen kann sie nicht. Der Wettmarkt ist ein Nullsummenspiel mit eingebauter Buchmachermarge, und wer langfristig gewinnen will, muss besser sein als der Durchschnitt. KI-Tools können dabei unterstützen, aber sie ersetzen nicht die Notwendigkeit, sich selbst weiterzubilden und kritisch zu denken. Am Ende des Tages ist erfolgreiches Wetten eine Kombination aus gutem Werkzeug, solider Methodik und der Disziplin, beides konsequent anzuwenden.
FAQ
Wie funktioniert künstliche Intelligenz bei Fußball-Value-Tipps?
KI-Systeme für Fußball-Value-Tipps basieren auf Machine-Learning-Algorithmen, die mit großen Mengen historischer Daten trainiert wurden. Diese Daten umfassen Spielergebnisse, detaillierte Statistiken wie Expected Goals, Formkurven, Verletzungsinformationen und Quotenentwicklungen. Der Algorithmus lernt aus diesen Daten, Muster zu erkennen, die für zukünftige Spiele relevant sein könnten, und berechnet daraus Wahrscheinlichkeiten für verschiedene Spielausgänge. Diese Wahrscheinlichkeiten werden dann mit den Buchmacherquoten verglichen. Wenn die KI-Wahrscheinlichkeit höher liegt als die von der Quote implizierte, entsteht Value, also ein positiver erwarteter Ertrag. Der Prozess ist datengetrieben und objektiv, ersetzt aber nicht die Notwendigkeit kritischer Überprüfung.
Kann man mit KI-Fußballtipps langfristig profitabel wetten?
Theoretisch ja, praktisch mit erheblichen Einschränkungen. KI kann dabei helfen, Wetten mit positivem Erwartungswert zu identifizieren, was über viele Wetten hinweg zu Gewinn führen sollte. Allerdings ist keine KI perfekt, Buchmacher passen ihre Quoten an, und die statistische Varianz bedeutet, dass auch gute Strategien kurz- bis mittelfristig Verluste produzieren können. Langfristiger Erfolg erfordert Disziplin, ausreichend Bankroll für Pechsträhnen, realistische Erwartungen und die Bereitschaft, die eigene Strategie kontinuierlich zu überprüfen. Garantierte Gewinne existieren nicht, und wer das Gegenteil behauptet, ist entweder uninformiert oder unehrlich. Der realistische Erwartungswert liegt bei einer leicht positiven Rendite über viele hundert Wetten, nicht bei schnellem Reichtum.
Was unterscheidet Value-Tipps von normalen KI-Prognosen?
Eine normale Prognose sagt voraus, welches Ergebnis am wahrscheinlichsten ist, etwa dass Bayern München gegen einen Abstiegskandidaten gewinnen wird. Ein Value-Tipp geht darüber hinaus und bewertet, ob die Wette auf dieses Ergebnis profitabel ist. Der entscheidende Unterschied liegt im Vergleich zwischen der geschätzten Wahrscheinlichkeit und der Buchmacherquote. Eine Wette auf den Bayern-Sieg mit einer Quote von 1,20 hat keinen Value, selbst wenn der Sieg zu 90 Prozent wahrscheinlich ist, denn die Quote impliziert bereits 83 Prozent. Value entsteht erst, wenn die eigene Wahrscheinlichkeitsschätzung höher liegt als die von der Quote implizierte. Man sucht also nicht nach den wahrscheinlichsten Ergebnissen, sondern nach den profitabelsten Wetten, was ein fundamental anderer Ansatz ist.